Automating RAG with IBM Granite Model and LangChain
Written by: Lukasz Cmielowski, PhD
The task
Use watsonx Granite Model Series and Langchain to answer State of the Union speech questions.
Note: the runnable code (jupyter notebook) can be found here.
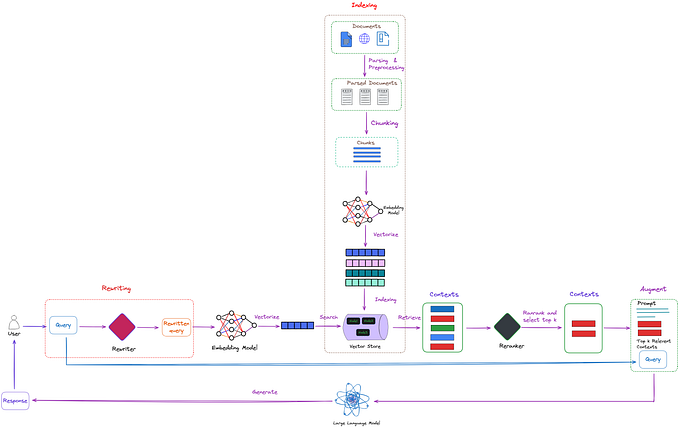
About Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is a versatile pattern that can unlock a number of use cases requiring factual recall of information, such as querying a knowledge base in natural language.
In its simplest form, RAG requires 3 steps:
- Index knowledge base passages (once)
- Retrieve relevant passage(s) from a knowledge base (for every user query)
- Generate a response by feeding the user query and the passage retrieved from the database into a large language model (for every user query).
Build up knowledge base
The most common approach in RAG is to create dense vector representations of the knowledge base in order to calculate the semantic similarity to a given user query.
In this basic example, we take the State of the Union speech content (filename), split it into chunks, embed it using an open-source embedding model, load it into Chroma, and then query it.
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
loader = TextLoader(filename)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
texts[0]Document(page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans. \n\nLast year COVID-19 kept us apart. This year we are finally together again. \n\nTonight, we meet as Democrats Republicans and Independents. But most importantly as Americans. \n\nWith a duty to one another to the American people to the Constitution. \n\nAnd with an unwavering resolve that freedom will always triumph over tyranny. \n\nSix days ago, Russia’s Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated. \n\nHe thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined. \n\nHe met the Ukrainian people. \n\nFrom President Zelenskyy to every Ukrainian, their fearlessness, their courage, their determination, inspires the world.', metadata={'source': 'state_of_the_union.txt'})The dataset we are using is already split into self-contained passages that can be ingested by Chroma.
Create an embedding function
Note that you can feed a custom embedding function to be used by chromadb. The performance of Chroma db may differ depending on the embedding model used.
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)Granite foundation models
IBM watsonx foundation models are among the list of LLM models supported by Langchain. This example shows how to communicate with Granite Model Series using Langchain.

First, provide the IBM Cloud user API key.
import os
from getpass import getpass
watsonx_api_key = getpass()
os.environ["WATSONX_APIKEY"] = watsonx_api_keyYou might need to adjust model parameters for different models or tasks, to do so please refer to documentation.
from ibm_watson_machine_learning.metanames import GenTextParamsMetaNames as GenParams
from ibm_watson_machine_learning.foundation_models.utils.enums import DecodingMethods
parameters = {
GenParams.DECODING_METHOD: DecodingMethods.GREEDY,
GenParams.MIN_NEW_TOKENS: 1,
GenParams.MAX_NEW_TOKENS: 100
}Initialize the WatsonxLLM class from Langchain with defined parameters and ibm/granite-13b-chat-v2. There is also instruct version of Granite v2 available ibm/granite-13b-instruct-v2.
Note: the Foundation Model requires project id that provides the context for the call. We will obtain the id from the project in which this notebook runs.
from langchain.llms import WatsonxLLM
project_id = os.environ["PROJECT_ID"]
watsonx_granite = WatsonxLLM(
model_id="ibm/granite-13b-chat-v2",
url="https://us-south.ml.cloud.ibm.com",
project_id=project_id,
params=parameters
)All set to use the IBM Granite model.
Generate a retrieval-augmented response to a question
Build the RetrievalQA chain to automate the RAG task.
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=watsonx_granite,
chain_type="stuff",
retriever=docsearch.as_retriever())That’s all. Just ask the question now.
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)" The president said that Ketanji Brown Jackson is one of our nation's top legal minds and will continue Justice Breyer's legacy of excellence.<|endoftext|>"The notebook with the code can be found here.