Bias detection and mitigation in IBM AutoAI
Written by: Lukasz Cmielowski, PhD, Dorota Lączak, Przemyslaw Czuba
In my previous articles, I’ve shown how we can use AutoAI to easily find the
best machine learning models. But guess what: it gets even better. From
now on, you can use AutoAI to automatically evaluate models for fairness
and mitigate the bias.
Terms and definitions
Before we get to the nitty-gritty, we need to start off by defining a few basic terms:
Fairness attribute: Bias or fairness is typically measured using some fairness attribute such as Gender, Ethnicity, Age, etc.
Monitored/Reference group: Fairness attributes that we want to measure bias against are called a monitored group. The remaining fairness attributes are called a reference group. If our fairness attribute is gender and we are trying to measure bias against females, then the monitored group would be “Female” and Reference group would be “Male”. Some sources refer to monitored and reference groups as unprivileged and privileged groups.
Favourable/Unfavourable outcome: A model can have favourable and
unfavourable outcomes. A good example might be “claim approved” being
a favourable outcome and “claim denied” being an unfavourable outcome.
Disparate impact (ratio): The percentage ratio of favourable outcomes in the monitored group measured against the percentage ratio of favourable outcomes in the reference group is called disparate impact (ratio). If the disparate impact value is below a certain threshold, we have detected bias

Typically, the threshold value for bias is 0.8 and thus if the disparate impact ratio is less than 0.8, the model is said to be biased.
For example, if 80% of claims made by males are approved, whereas only 60% of claims made by females are approved, then the disparate impact will be 60/80 = 0.75. Less than the usual bias threshold but it might be a good idea to have a look at our model.
Bias detection
To detect bias in a model, you must define fairness attributes (protected attributes), such as Age or Sex. You can do that manually or decide that AutoAI should do that for you.

Manual mode
In manual mode, user provides the fairness configuration, including protected_attributes, monitored/referenced groups and favorable/unfavorable labels. This configuration is used by AutoAI to calculate the disparate_impact metric for each trained pipeline and each protected attribute
fairness_info = {
"protected_attributes": [
{"feature": "Sex", "reference_group": ['male'], "monitored_group": ['female']},
{"feature": "Age", "reference_group": [[26, 75]], "monitored_group": [[18, 25]]}
],
"favorable_labels": ["No Risk"],
"unfavorable_labels": ["Risk"],
}Automatic mode
In automatic mode, AutoAI automatically identifies whether any known protected attributes are present in a model. When AutoAI detects these attributes, it automatically configures the disparate impact metric calculation for each pipeline and each attribute present, to ensure that bias against these potentially sensitive attributes is tracked. Currently, AutoAI detects and recommends monitors for the following protected attributes:
- sex
- ethnicity
- marital status
- age
- zip code or postal code
In addition to detecting protected attributes, AutoAI finds which values within each attribute should be set as the monitored and the reference values. For example, within the Sex attribute, the bias calculation is configured such that Female is the monitored value, and Male is the reference value.
Automatic bias evaluation help to speed up configuration and ensure that you are checking your AI models for fairness against sensitive attributes. As regulators begin to turn a sharper eye on algorithmic bias, it is becoming more critical that organisations have a clear understanding of how their models are performing, and whether they are producing unfair outcomes for certain groups.
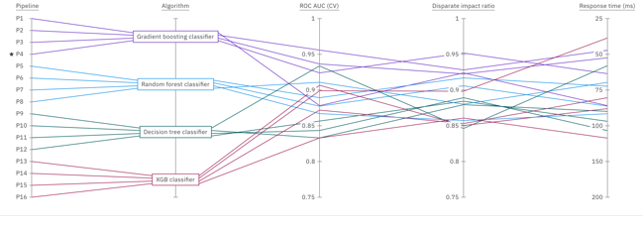
The python API provides visualize method that can be used for getting fairness insights, with outcome distribution against specific pipelines and protected attributes.
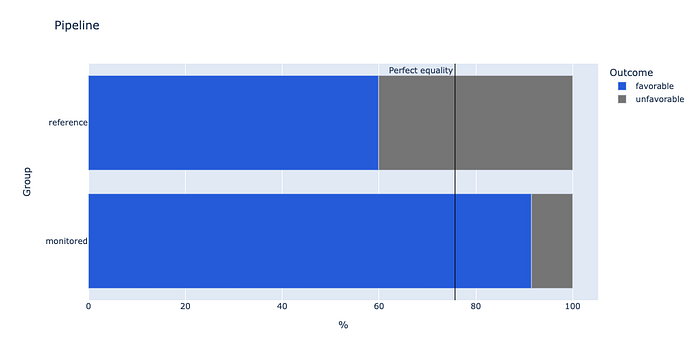
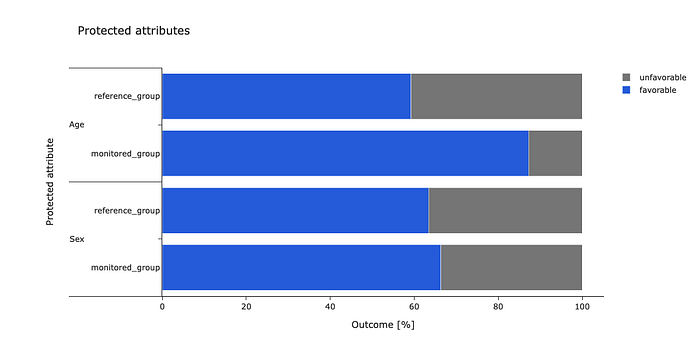
Bias mitigation
In order to mitigate bias, IBM Watson AutoAI uses combined scorers accuracy_and_disparate_impact (classification) or r2_and_disparate_impact (regression); both of them scikit-learn compatible. The combined scorers are used in the AutoAI’s best pipeline search process, to find fair and accurate models. Higher score results indicate better outcomes: accurate and fair.
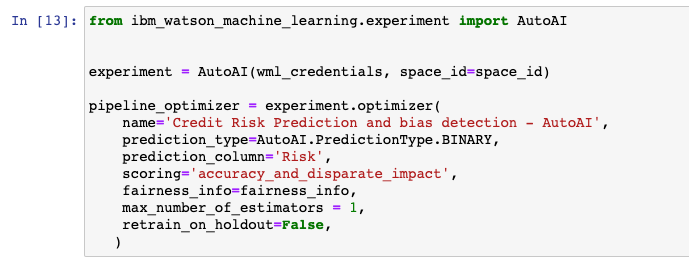
Integration with 3rd party packages
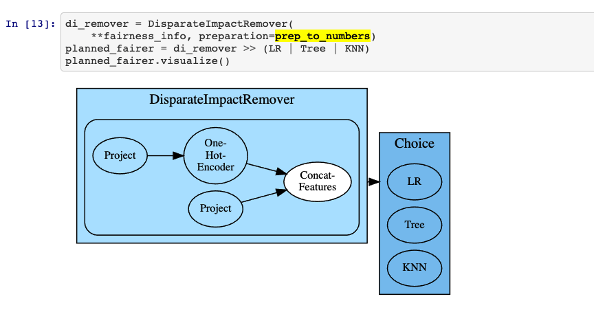
AutoAI trained pipelines can be easily refactored using available packages
like: lale or AIF360. The scorer methods or bias mitigation methods can be
used to work with AutoAI pipelines. For example, you can refine the AutoAI
pipeline by injecting the DisparateImpactRemover method, to mitigate the
bias in the model
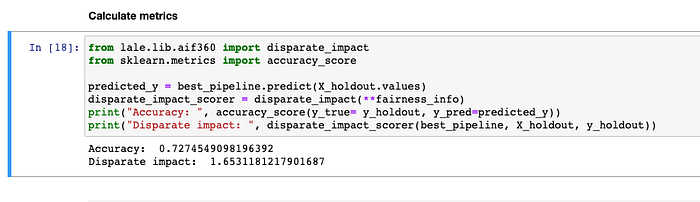
You can use disparate_impact scorer function to evaluate the fairness of the AutoAI model.
Summing up: Today’s IBM AutoAI not only find the best model but also ensures that the model is fair. Check this new feature out on on IBM Cloud.
